基本教程¶
注意
此页面使用两种不同的语法变体
Cython 特定的
cdef语法,旨在使类型声明简洁,并易于从 C/C++ 的角度阅读。纯 Python 语法,允许在 纯 Python 代码 中使用静态 Cython 类型声明,遵循 PEP-484 类型提示和 PEP 526 变量注释。
要在 Python 语法中使用 C 数据类型,您需要在要编译的 Python 模块中导入特殊的
cython模块,例如import cython
如果您使用纯 Python 语法,我们强烈建议您使用最新的 Cython 3 版本,因为与 0.29.x 版本相比,这里已经进行了重大改进。
Cython 的基础¶
Cython 的基本性质可以概括如下:Cython 是带有 C 数据类型的 Python。
Cython 是 Python:几乎所有 Python 代码都是有效的 Cython 代码。(有一些 限制,但这种近似将暂时适用。)Cython 编译器会将其转换为 C 代码,该代码对 Python/C API 进行等效调用。
但 Cython 不止于此,因为参数和变量可以声明为具有 C 数据类型。操作 Python 值 和 C 值的代码可以自由混合,并在可能的情况下自动进行转换。Python 操作的引用计数维护和错误检查也是自动的,并且 Python 异常处理机制的全部功能(包括 try-except 和 try-finally 语句)都可供您使用——即使在操作 C 数据的过程中也是如此。
Cython Hello World¶
由于 Cython 可以接受几乎所有有效的 Python 源文件,因此入门最难的事情之一就是弄清楚如何编译扩展。
所以让我们从规范的 Python hello world 开始
print("Hello World")
将此代码保存在名为 helloworld.pyx 的文件中。现在我们需要创建 setup.py,它类似于 Python Makefile(有关更多信息,请参见 源文件和编译)。您的 setup.py 应该如下所示
from setuptools import setup
from Cython.Build import cythonize
setup(
ext_modules = cythonize("helloworld.pyx")
)
要使用它来构建 Cython 文件,请使用以下命令行选项
$ python setup.py build_ext --inplace
这将在您的本地目录中留下一个名为 helloworld.so(在 Unix 中)或 helloworld.pyd(在 Windows 中)的文件。现在要使用此文件:启动 Python 解释器,并像使用常规 Python 模块一样导入它
>>> import helloworld
Hello World
恭喜!您现在知道如何构建 Cython 扩展。但到目前为止,这个例子并没有真正说明为什么要使用 Cython,所以让我们创建一个更现实的例子。
pyximport:面向开发人员的 Cython 编译¶
如果您的模块不需要任何额外的 C 库或特殊的构建设置,那么您可以使用 pyximport 模块(最初由 Paul Prescod 开发)在导入时直接加载 .pyx 文件,而无需每次更改代码时都运行 setup.py 文件。它与 Cython 一起提供和安装,可以使用以下方式使用
>>> import pyximport; pyximport.install()
>>> import helloworld
Hello World
Pyximport 模块也对普通 Python 模块提供了实验性的编译支持。这允许您在 Python 导入的每个 .pyx 和 .py 模块上自动运行 Cython,包括标准库和已安装的包。Cython 仍然无法编译许多 Python 模块,在这种情况下,导入机制将回退到加载 Python 源模块。.py 导入机制的安装方式如下
>>> pyximport.install(pyimport=True)
请注意,不建议让 Pyximport 在最终用户端构建代码,因为它会挂钩到他们的导入系统。为最终用户提供服务的最佳方式是在 wheel 打包格式中提供预构建的二进制包。
斐波那契乐趣¶
从官方 Python 教程中,定义了一个简单的斐波那契函数
from __future__ import print_function
def fib(n):
"""Print the Fibonacci series up to n."""
a, b = 0, 1
while b < n:
print(b, end=' ')
a, b = b, a + b
print()
现在按照 Hello World 示例的步骤,我们首先将文件重命名为具有 .pyx 扩展名,比如 fib.pyx,然后我们创建 setup.py 文件。使用为 Hello World 示例创建的文件,您只需要更改 Cython 文件名和生成的模块名,这样我们就有
from setuptools import setup
from Cython.Build import cythonize
setup(
ext_modules=cythonize("fib.pyx"),
)
使用与 helloworld.pyx 相同的命令构建扩展
$ python setup.py build_ext --inplace
并使用新的扩展
>>> import fib
>>> fib.fib(2000)
1 1 2 3 5 8 13 21 34 55 89 144 233 377 610 987 1597
素数¶
这是一个展示了一些功能的小例子。它是一个用于查找素数的例程。您告诉它您想要多少个素数,它会将它们作为 Python 列表返回。
1def primes(nb_primes: cython.int):
2 i: cython.int
3 p: cython.int[1000]
4
5 if nb_primes > 1000:
6 nb_primes = 1000
7
8 if not cython.compiled: # Only if regular Python is running
9 p = [0] * 1000 # Make p work almost like a C array
10
11 len_p: cython.int = 0 # The current number of elements in p.
12 n: cython.int = 2
13 while len_p < nb_primes:
14 # Is n prime?
15 for i in p[:len_p]:
16 if n % i == 0:
17 break
18
19 # If no break occurred in the loop, we have a prime.
20 else:
21 p[len_p] = n
22 len_p += 1
23 n += 1
24
25 # Let's copy the result into a Python list:
26 result_as_list = [prime for prime in p[:len_p]]
27 return result_as_list
1def primes(int nb_primes):
2 cdef int n, i, len_p
3 cdef int[1000] p
4
5 if nb_primes > 1000:
6 nb_primes = 1000
7
8
9
10
11 len_p = 0 # The current number of elements in p.
12 n = 2
13 while len_p < nb_primes:
14 # Is n prime?
15 for i in p[:len_p]:
16 if n % i == 0:
17 break
18
19 # If no break occurred in the loop, we have a prime.
20 else:
21 p[len_p] = n
22 len_p += 1
23 n += 1
24
25 # Let's copy the result into a Python list:
26 result_as_list = [prime for prime in p[:len_p]]
27 return result_as_list
您会看到它从一个普通的 Python 函数定义开始,除了参数 nb_primes 被声明为类型 int。这意味着传递的对象将被转换为 C 整数(或者如果无法转换,则会引发 TypeError.)。
现在,让我们深入研究函数的核心
2i: cython.int
3p: cython.int[1000]
11len_p: cython.int = 0 # The current number of elements in p.
12n: cython.int = 2
第 2、3、11 和 12 行使用变量注释定义一些局部 C 变量。结果在处理过程中存储在 C 数组 p 中,并在最后(第 26 行)复制到 Python 列表中。
2cdef int n, i, len_p
3cdef int[1000] p
第 2 和 3 行使用 cdef 语句定义一些局部 C 变量。结果在处理过程中存储在 C 数组 p 中,并在最后(第 26 行)复制到 Python 列表中。
注意
您不能以这种方式创建非常大的数组,因为它们是在 C 函数调用 堆栈 上分配的,这是一个相当宝贵和稀缺的资源。要请求更大的数组,甚至是在运行时才知道长度的数组,您可以学习如何有效地使用 C 内存分配、Python 数组 或 NumPy 数组 与 Cython。
5if nb_primes > 1000:
6 nb_primes = 1000
与 C 一样,声明静态数组需要在编译时知道大小。我们确保用户不会设置超过 1000 的值(否则我们会遇到段错误,就像在 C 中一样)
8if not cython.compiled: # Only if regular Python is running
9 p = [0] * 1000 # Make p work almost like a C array
当我们从 Python 运行这段代码时,我们必须初始化数组中的项目。最简单的方法是用零填充它(如第 8-9 行所示)。另一方面,当我们用 Cython 编译它时,数组的行为将与 C 中一样。它在函数调用堆栈上分配,具有 1000 个项目的固定长度,这些项目包含上次使用该内存时的任意数据。然后,我们将在计算中覆盖这些项目。
10len_p: cython.int = 0 # The current number of elements in p.
11n: cython.int = 2
12while len_p < nb_primes:
10len_p = 0 # The current number of elements in p.
11n = 2
12while len_p < nb_primes:
第 11-13 行设置了一个 while 循环,该循环将测试数字候选素数,直到找到所需的素数数量。
14# Is n prime?
15for i in p[:len_p]:
16 if n % i == 0:
17 break
第 15-16 行试图将候选数除以迄今为止找到的所有素数,这一点特别令人感兴趣。因为没有引用 Python 对象,所以循环完全被翻译成 C 代码,因此运行速度非常快。您会注意到我们遍历 p C 数组的方式。
15for i in p[:len_p]:
循环被转换为快速的 C 循环,其工作方式与迭代 Python 列表或 NumPy 数组相同。如果您没有使用 [:len_p] 切片 C 数组,那么 Cython 将遍历数组的 1000 个元素。
19# If no break occurred in the loop, we have a prime.
20else:
21 p[len_p] = n
22 len_p += 1
23n += 1
如果没有发生中断,则意味着我们找到了一个素数,并且 else 第 20 行之后的代码块将被执行。我们将找到的素数添加到 p 中。如果您发现 for 循环之后的 else 很奇怪,请知道这是 Python 语言中鲜为人知的功能,Cython 以 C 速度为您执行它。如果 for-else 语法让您感到困惑,请查看这篇优秀的 博客文章。
25# Let's copy the result into a Python list:
26result_as_list = [prime for prime in p[:len_p]]
27return result_as_list
在第 26 行,在返回结果之前,我们需要将 C 数组复制到 Python 列表中,因为 Python 无法读取 C 数组。Cython 可以自动将许多 C 类型从 Python 类型转换而来,反之亦然,如 类型转换 文档中所述,因此我们可以在这里使用简单的列表推导将 C int 值复制到 Python int 对象的 Python 列表中,Cython 会在过程中自动创建这些对象。您也可以手动遍历 C 数组并使用 result_as_list.append(prime),结果将相同。
您会注意到我们声明 Python 列表的方式与在 Python 中完全相同。因为变量 result_as_list 没有明确声明类型,所以它被假定为保存 Python 对象,并且从赋值来看,Cython 也知道确切类型是 Python 列表。
最后,在第 27 行,一个普通的 Python return 语句返回结果列表。
使用 Cython 编译器编译 primes.py 会生成一个扩展模块,我们可以在交互式解释器中尝试如下操作
使用 Cython 编译器编译 primes.pyx 会生成一个扩展模块,我们可以在交互式解释器中尝试如下操作
>>> import primes
>>> primes.primes(10)
[2, 3, 5, 7, 11, 13, 17, 19, 23, 29]
看,它起作用了!如果您好奇 Cython 为您节省了多少工作,请查看为该模块生成的 C 代码。
Cython 有一种方法可以可视化与 Python 对象和 Python 的 C-API 交互的位置。为此,将 annotate=True 参数传递给 cythonize()。它会生成一个 HTML 文件。让我们看看
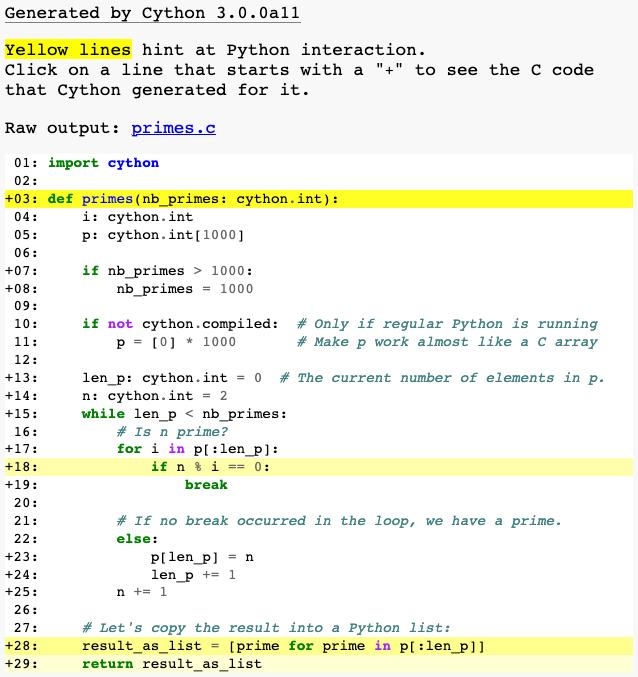
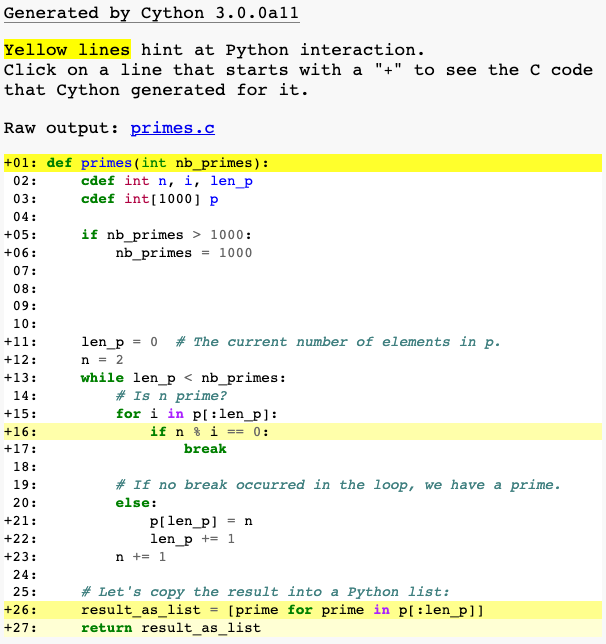
如果一行是白色的,则意味着生成的代码不会与 Python 交互,因此将像普通的 C 代码一样快速运行。黄色越深,该行中与 Python 的交互就越多。这些黄色的行通常会操作 Python 对象,引发异常,或执行除简单快速 C 代码可以轻松转换为的简单快速 C 代码之外的其他类型的更高级操作。函数声明和返回使用 Python 解释器,因此这些行是黄色的是有道理的。列表推导也是如此,因为它涉及创建 Python 对象。但是 if n % i == 0: 为什么是黄色的?我们可以检查生成的 C 代码来理解
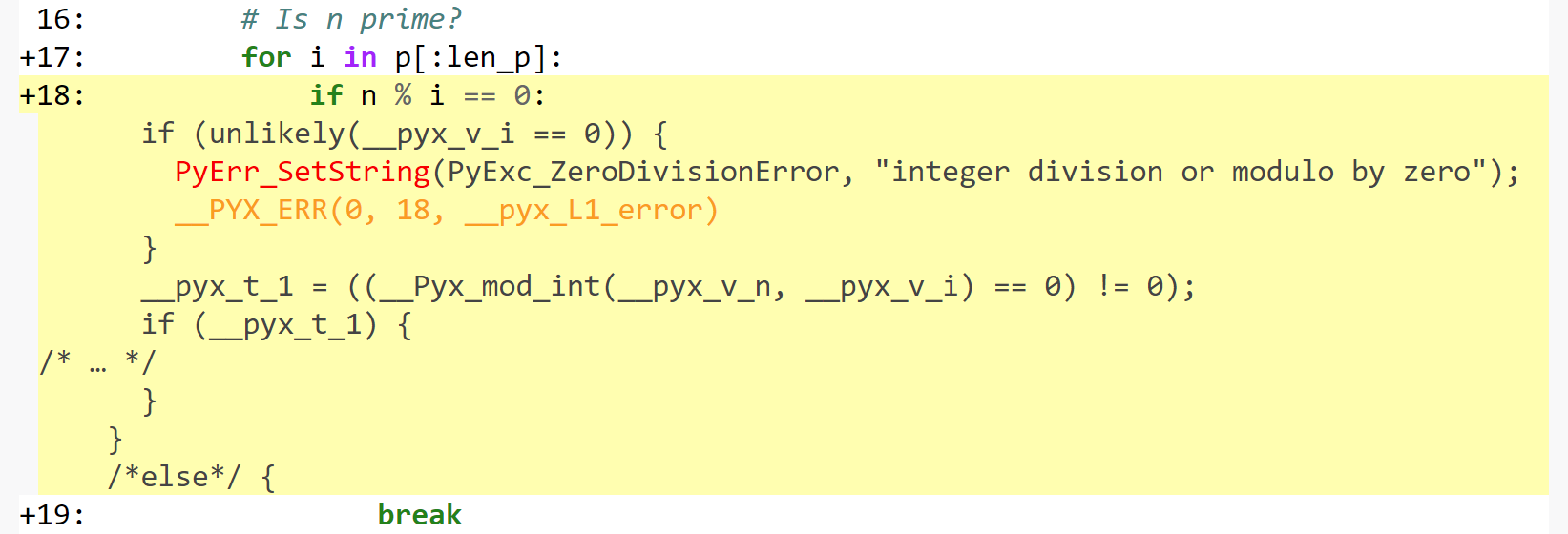
我们可以看到一些检查正在发生。因为 Cython 默认使用 Python 行为,所以该语言将在运行时执行除法检查,就像 Python 一样。您可以使用 编译器指令 禁用这些检查。
现在让我们看看即使存在除法检查,我们是否能获得速度提升。让我们编写相同的程序,但在 Python 中
def primes(nb_primes):
p = []
n = 2
while len(p) < nb_primes:
# Is n prime?
for i in p:
if n % i == 0:
break
# If no break occurred in the loop
else:
p.append(n)
n += 1
return p
可以使用 Cython 编译普通的(未注释的) .py 文件。让我们创建一个 primes_python 的副本,并将其命名为 primes_python_compiled,以便能够将其与(未编译的)Python 模块进行比较。然后我们使用 Cython 编译该文件,而不更改代码。现在 setup.py 看起来像这样
from setuptools import setup
from Cython.Build import cythonize
setup(
ext_modules=cythonize(
['primes.py', # Cython code file with primes() function
'primes_python_compiled.py'], # Python code file with primes() function
annotate=True), # enables generation of the html annotation file
)
from setuptools import setup
from Cython.Build import cythonize
setup(
ext_modules=cythonize(
['primes.pyx', # Cython code file with primes() function
'primes_python_compiled.py'], # Python code file with primes() function
annotate=True), # enables generation of the html annotation file
)
现在我们可以确保这两个程序输出相同的值
>>> import primes, primes_python, primes_python_compiled
>>> primes_python.primes(1000) == primes.primes(1000)
True
>>> primes_python_compiled.primes(1000) == primes.primes(1000)
True
现在可以比较速度了
python -m timeit -s "from primes_python import primes" "primes(1000)"
10 loops, best of 3: 23 msec per loop
python -m timeit -s "from primes_python_compiled import primes" "primes(1000)"
100 loops, best of 3: 11.9 msec per loop
python -m timeit -s "from primes import primes" "primes(1000)"
1000 loops, best of 3: 1.65 msec per loop
primes_python 的 cythonize 版本比 Python 版本快 2 倍,而无需更改一行代码。Cython 版本比 Python 版本快 13 倍!是什么导致了这种情况?
- 多方面原因
在这个程序中,每行代码的计算量非常少。因此,Python 解释器的开销非常重要。如果你要在每行代码中进行大量计算,情况就会大不相同。例如,使用 NumPy。
数据局部性。使用 C 时,CPU 缓存中可能可以容纳更多数据,而使用 Python 时则不然。因为 Python 中的一切都是对象,每个对象都实现为字典,这不利于缓存。
通常,加速比在 2 倍到 1000 倍之间。这取决于你调用 Python 解释器的次数。与往常一样,请记住在添加类型之前进行性能分析。添加类型会降低代码的可读性,因此请适度使用。
使用 C++ 的素数¶
使用 Cython,也可以利用 C++ 语言,特别是,C++ 标准库的一部分可以直接从 Cython 代码中导入。
让我们看看使用 C++ 标准库中的 vector 时,我们的代码会变成什么样子。
注意
C++ 中的 Vector 是一种数据结构,它基于可调整大小的 C 数组实现列表或堆栈。它类似于 Python array 标准库模块中的 array 类型。有一个名为 reserve 的方法,如果你事先知道要放入向量中的元素数量,它可以避免复制。有关更多详细信息,请参阅 cppreference 上的此页面。
1# distutils: language=c++
2
3import cython
4from cython.cimports.libcpp.vector import vector
5
6def primes(nb_primes: cython.uint):
7 i: cython.int
8 p: vector[cython.int]
9 p.reserve(nb_primes) # allocate memory for 'nb_primes' elements.
10
11 n: cython.int = 2
12 while p.size() < nb_primes: # size() for vectors is similar to len()
13 for i in p:
14 if n % i == 0:
15 break
16 else:
17 p.push_back(n) # push_back is similar to append()
18 n += 1
19
20 # If possible, C values and C++ objects are automatically
21 # converted to Python objects at need.
22 return p # so here, the vector will be copied into a Python list.
警告
上面/此页面提供的代码通过 cimport (cython.cimports) 使用外部本机(非 Python)库。Cython 编译支持这一点,但纯 Python 不支持。尝试从 Python(不进行编译)运行此代码将在访问外部库时失败。这在 调用 C 函数 中有更详细的说明。
1# distutils: language=c++
2
3
4from libcpp.vector cimport vector
5
6def primes(unsigned int nb_primes):
7 cdef int n, i
8 cdef vector[int] p
9 p.reserve(nb_primes) # allocate memory for 'nb_primes' elements.
10
11 n = 2
12 while p.size() < nb_primes: # size() for vectors is similar to len()
13 for i in p:
14 if n % i == 0:
15 break
16 else:
17 p.push_back(n) # push_back is similar to append()
18 n += 1
19
20 # If possible, C values and C++ objects are automatically
21 # converted to Python objects at need.
22 return p # so here, the vector will be copied into a Python list.
第一行是编译器指令。它告诉 Cython 将你的代码编译为 C++。这将启用 C++ 语言特性和 C++ 标准库的使用。请注意,无法使用 pyximport 将 Cython 代码编译为 C++。你应该使用 setup.py 或笔记本运行此示例。
你可以看到,向量的 API 类似于 Python 列表的 API,有时可以用作 Cython 中的直接替换。
有关在 Cython 中使用 C++ 的更多详细信息,请参阅 在 Cython 中使用 C++。
语言细节¶
有关 Cython 语言的更多信息,请参阅 语言基础。要直接开始在数值计算环境中使用 Cython,请参阅 类型化内存视图。
